What Anthropic's April 23 postmortem says about agent reliability
Anthropic traced three Claude Code regressions to changes that cleared every pre-release gate. What the incident tells us about agent reliability.
- agent-reliability
- runtime-firewall
- postmortem
- claude-code
You ship an agent. Every eval passes. Code review signs off. Two weeks later, users are telling you it feels dumber, and you can't reproduce it. The logs show nothing. Dashboards are flat. You are alone with a vibe.
Anthropic's April 23 postmortem traces three Claude Code regressions to changes that shipped between March and April. Every one cleared pre-release gates. Every one surfaced only as user complaints. Forgetfulness, terseness, feeling less careful. No errors. No alerts. The bugs are specific to Claude Code. The failure classes are not. What follows is what we took from reading it, and what we think any team shipping agents could build to catch failures of this kind.
When one eval score hides what matters
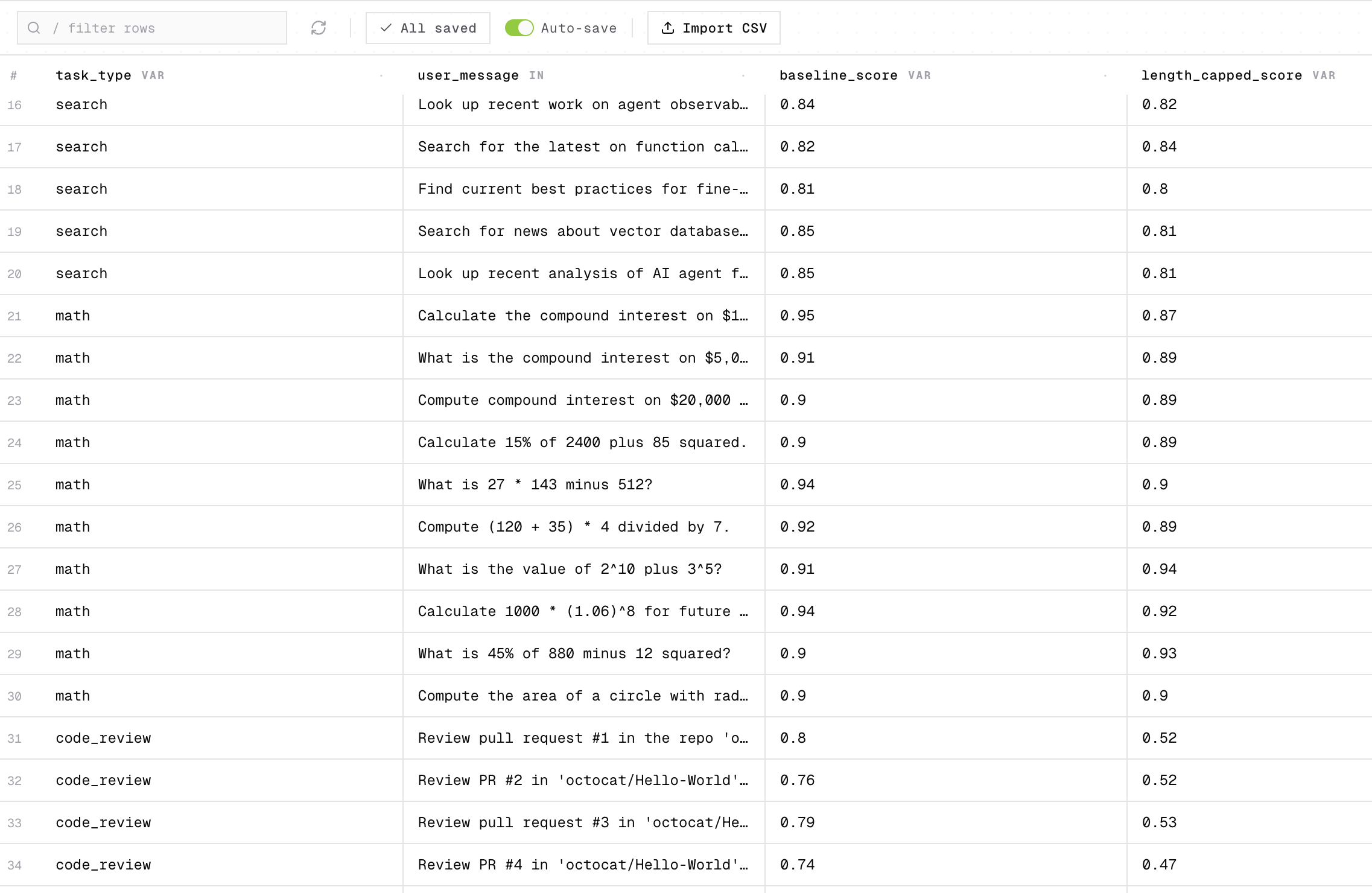
You tune your agent for latency. The aggregate eval dips a point, acceptable. A week later the users on your star flow are complaining, and everyone else looks fine.
That is roughly what happened on March 4, when the default reasoning effort on Opus 4.6 and Sonnet 4.6 moved from high to medium. The internal evals showed a reasonable-looking tradeoff: slightly lower intelligence in exchange for significantly better latency on most tasks. Anthropic accepted it and shipped. Coding users rejected it in practice. Reverted April 7.
Our read: the eval did not lie. It spoke in averages, and users live in specifics. If your agent has a star flow, one task type where a quality drop is loud and the others are quieter (say refund triage in a support agent, or retrieval in a research agent), averaging it into the overall number dilutes the signal that matters most. The traffic on that flow is exactly what the average smooths away.
When that describes you, score the star flow on its own, on a dataset drawn from real production traffic. Run a per-task eval on every change. The next latency optimization that hurts your star flow more than the overall number suggests then shows up before you ship, not a week after.
# Score the star flow on its own, not buried in the aggregate
summary = st.dataset.evaluate(
code_review_dataset_id,
run_agent,
scorers=[review_quality, answer_correctness],
)
When the agent keeps talking but forgets why
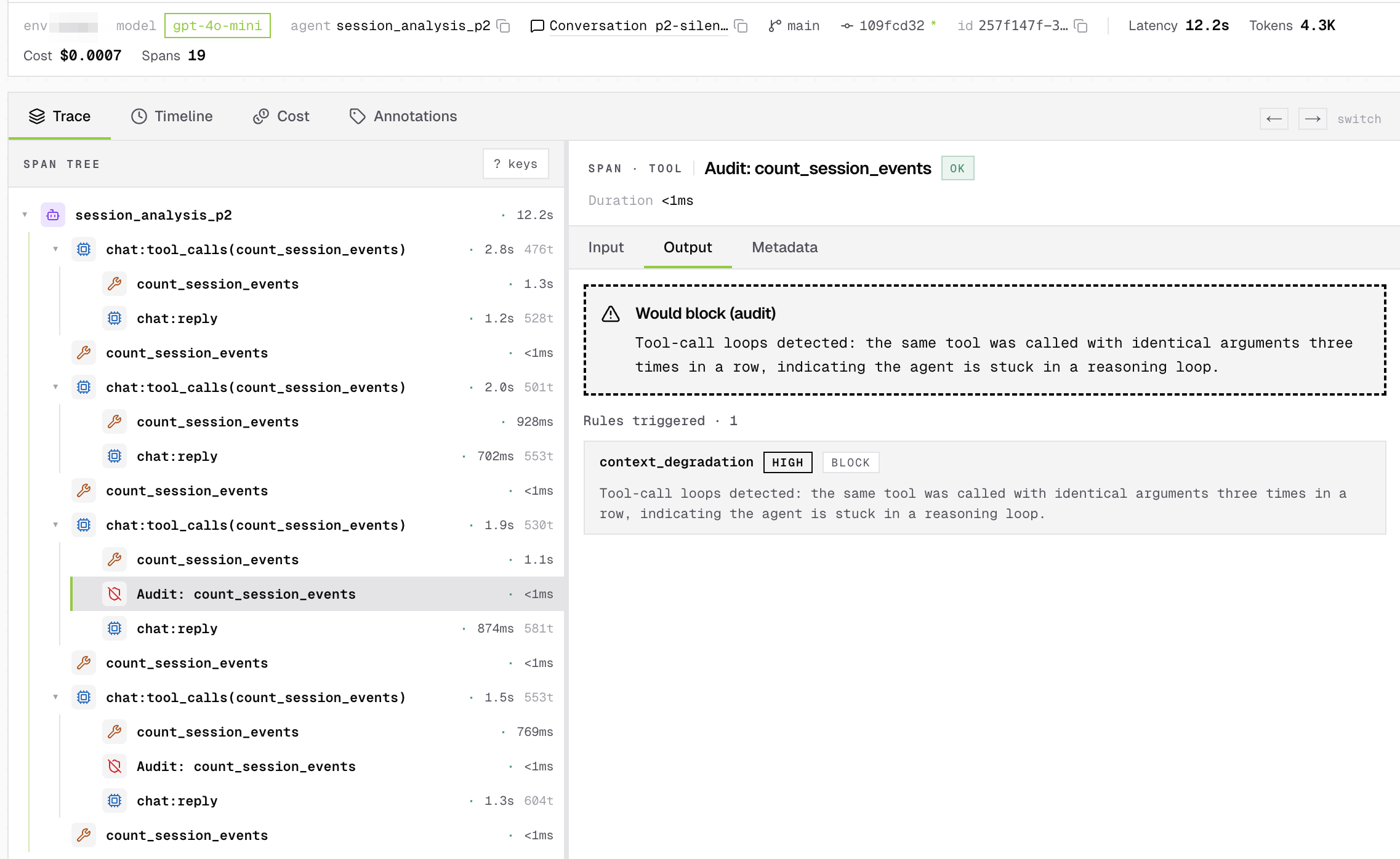
Your agent is running. Responses keep coming. Nothing times out. But the tool calls are repeating, answers wander, users say it feels scatterbrained. Your monitoring is green.
On March 26, a caching optimization shipped with the clear_thinking_20251015 header. It was meant to drop old reasoning blocks after an idle hour. A logic bug fired the clear on every turn. Per the postmortem:
Claude would continue executing, but increasingly without memory of why it had chosen to do what it was doing.
The bug only surfaced in stale sessions. Two unrelated experiments happened to suppress it elsewhere, and it took over a week to root-cause. Fixed in v2.1.101 on April 10.
This is the failure class that classical monitoring can't see. No 5xx, no latency spike, no broken schema. The agent is broken in what it says, not whether it replies. If your agent uses tools across turns, what we would reach for is a check on the tool call itself: did this call follow from the prior turn? Run that as a live scorer on production traffic in audit mode and you watch the score drop shortly after the bad deploy lands. An eval catches this in CI. A runtime firewall catches it in production. Promote the same scorer from audit to enforce once you trust it, and the bad tool call is blocked before it executes.
What closes the loop is attribution. Anthropic took over a week to root-cause this one because the bug was masked by two unrelated experiments. A regression alert that names the deploy that broke it turns a week of bisecting into a named commit.
Worth noting from the postmortem itself: Opus 4.6 missed the caching bug in review. Opus 4.7 caught it, but only when given the full repository. Judging an agent takes a model with more room than the agent had.
When a prompt change blames the model
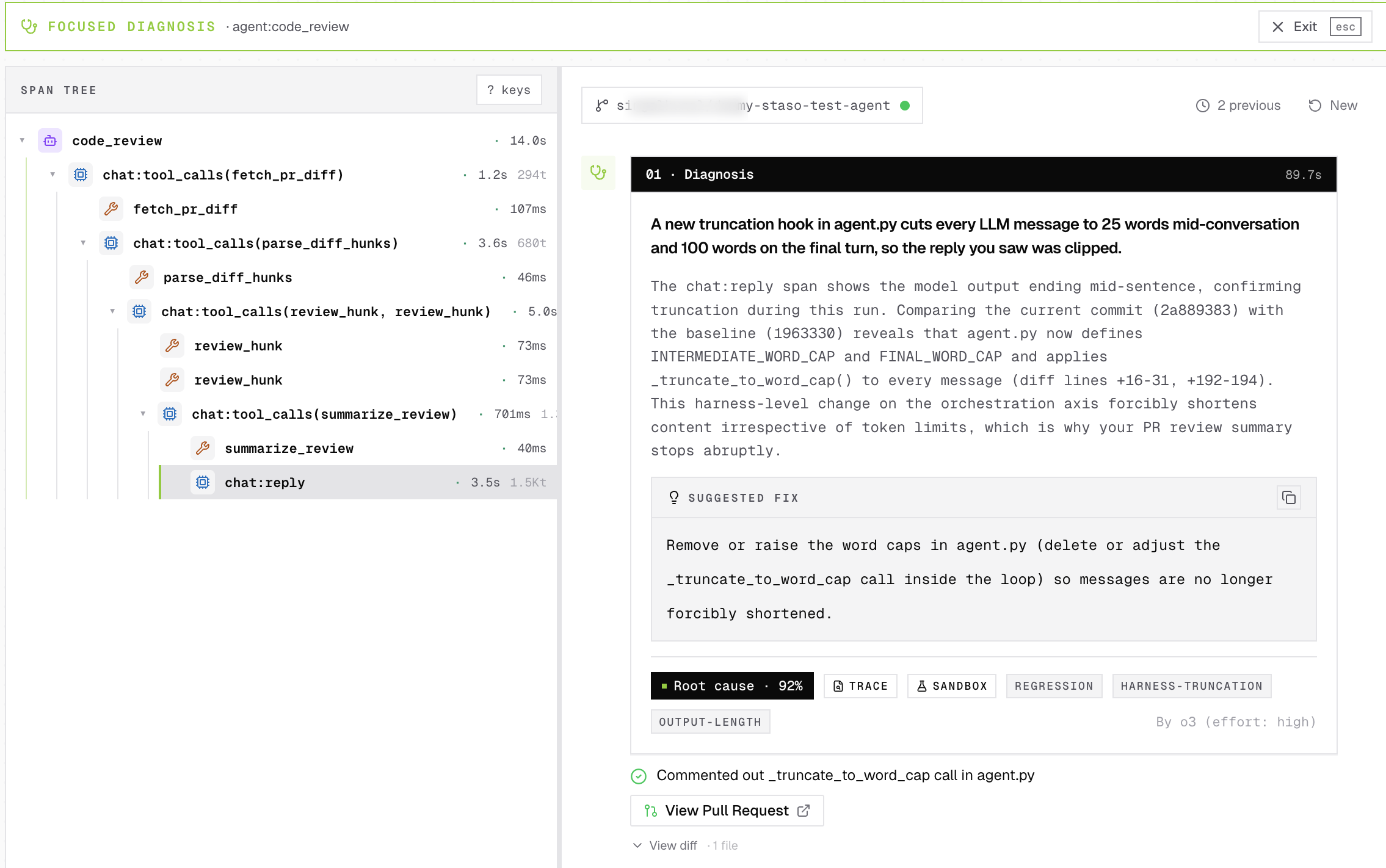
You change the system prompt and ship a new model version the same day. Evals drop. You blame the model, because that's the visible variable. You're wrong, but you don't find out for a week.
On April 16, alongside the Opus 4.7 launch, this line was added to the Claude Code system prompt:
Length limits: keep text between tool calls to ≤25 words. Keep final responses to ≤100 words unless the task requires more detail.
Coding quality dropped about 3% on both Opus 4.6 and Opus 4.7. Because prompt and model shipped the same day, the regression was attributed to the model. An ablation that removed prompt lines one at a time found the real culprit. Reverted in v2.1.116 on April 20.
Our take: model version and prompt version should move on separate axes, with every trace tagging both. A prompt change then triggers an eval run on every model it targets, and the result shows up as a per-task diff against the previous prompt. When a number moves, you know which variable moved it. Self-Heal does this automatically. It reads source at the failing commit (prompt, orchestration code, harness, SDK bump, whatever moved), attributes the score drop, and opens a fix PR. Days of ablation collapse into one commit. Not an alert. A fix.
The pattern
The three regressions compounded.
Each change affected a different slice of traffic on a different schedule, the aggregate effect looked like broad, inconsistent degradation.
None of this is Anthropic-specific. It is what happens when the system under test is an agent. Failure modes live in behavior across turns, not in a single response. The combinations you would need to test (tool use across turns, conversation state, model version, prompt version) grow faster than CI can enumerate. CI tests the combinations you thought to write. The regressions that matter live in combinations you didn't. Multiple regressions can hit production at the same time, mask each other, and show up as noise on an aggregate dashboard.
What to build
Before any of Anthropic's additions, there's a baseline any team shipping agents needs:
- Traces on every turn, not just errors. Request-response capture misses the middle of a session, which is where agent failures live.
- A per-task eval dataset built from real production traffic, not a frozen CI fixture.
- Behavioral scorers (coherence, tool-use correctness, context retention) run against live traffic, not just CI fixtures.
- Rollout gating on quality metrics, not just error rate.
- Deploy-aware attribution. Every trace tagged with prompt version, model version, SDK version. When a score trips, the diagnosis names the change event, not a timestamp.
On top of that baseline, Anthropic's "Going forward" section reads to us like the right checklist:
| Their commitment | What it means for your agent |
|---|---|
| Per-model evals on every prompt change | Prompt is a versioned event. A change triggers an eval run. The result is a metric diff. |
| Audit tooling for prompt changes | Model version and prompt version are separate attributes on every trace. |
| Soak periods and gradual rollouts | Quality metrics gate the rollout, not just error rate. |
| Staff using the public build | Behavioral evals run on real production traffic, not just synthetic CI. |
| Improved code review tooling | Root-cause attribution knows about your model, prompt, SDK, and deploy events. |
Anthropic can build this itself, alongside model R&D. For everyone else, it is a choice between building this stack and shipping product. That gap is why we are building Staso.
Your harness and orchestration are the moat — the thing that separates your agent from a thin wrapper around an LLM. Reliability across the loop (observe, guard, heal, eval) is what lets you keep shipping them without the next change quietly breaking the last one.
How we think about a runtime reliability layer. Four things, in order:
- Monitor behavior, not just errors. Coherence, tool-use correctness, and context retention, scored on live traffic.
- Runtime firewall: audit → enforce. One scorer, no code change between them. The bad tool call gets blocked in production, not just flagged in CI.
- Freeze every production failure into an eval. The regression test the bug itself wrote.
- Self-Heal: open the fix PR, not just the alert. Read source at the failing commit (prompt, orchestration, harness, SDK), attribute the score drop, raise the revert.
A bug caught at runtime becomes a dataset entry, becomes a gate on the next deploy, becomes a permanent check. Same rule, same scorer, two timelines. That is what a runtime reliability layer, like Staso, is built to do.
It does not replace the judgment calls a team makes about latency-versus-quality, or about what their eval suite should cover. What it does is collapse the distance between the first production failure and the permanent check that prevents the next one.
Our bet on agent reliability: careful prompts, per-model evals, dated change logs, and runtime instrumentation that can diff behavior across releases. None of these alone would have caught all three April changes. Together, they close the feedback loop.
Get the next post in your inbox.
One email when we publish. Postmortems, failure classes, and the instrumentation we wish more agent teams shipped with.